Where a model looks is not why it decides
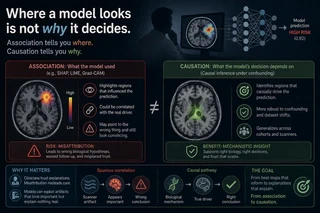
Ask a deep learning model why it flagged a scan, and most tools hand back a heat map. Here is where I looked. It feels like an answer. It is not the one you asked.
Tools like SHAP and LIME score how much each feature moved a prediction. These are measures of association, and association is slippery. A region can stand out because it drives the outcome, or because it travels alongside something that does. The map looks the same either way, and a confident picture of the wrong thing is worse than no picture at all.
In medical imaging the stakes sharpen that confusion. A clinician who trusts a misattributed region may chase the wrong biology. A model that latched onto a scanner artifact can pass every saliency check while explaining nothing real.
My current work asks a different question. Not which features correlate with a prediction, but which ones cause it, in a form a researcher can actually use. The aim is explanation that holds up under confounding and carries across cohorts, so a flagged region reflects mechanism rather than coincidence.
Explanation is meant to build trust. It earns that trust only when it points at causes. That is the gap I am working to close.
